R Markdown 大家庭简述
R Markdown 大家庭简述
本文仅代表2021年6月的笔者的理解,文中的错误、遗漏等问题欢迎指正。
前言
自笔者学习使用 rmarkdown、knitr、bookdown 等文档创作与生成技术以来已有将近一年的时间了,期间走马观花地看了一些相关的技术博客与书籍,在使用上愈加娴熟。但是在使用过程中遇到过许多“奇怪的”Bug,并且不论在中文网站还是StackOverflow,都无法找到能准确解决问题的方法。这在一定程度上是这些软件的功能还未完全稳定的缘故(与用 3.1415926... 做版本号的 Tex 不同),但也有 R Markdown 系列技术缺少内容较为集中和全面的文档的原因。为了更好地学习和理解这些软件的基本原理、能力边界和发展趋势,不做一名盲目且被动的软件使用者,笔者参考各类资料,结合自己的理解完成这篇关于 R Markdown 的简述。
倒不是非得对 R Markdown 的原理了解有多深,但了解了它们能做什么,更能够在 Microsoft Word、Tex 和 R Markdown 中选择最适合的解决方案。
从文学编程到可重复的统计研究
代码到底是给人读的,还是给机器运行的呢?提出文学编程(Literate Programming)的 Knuth 老先生认为我们的代码应该向人们解释自己希望让计算机干什么。不过大家在 Literate 这个词上的理解似乎各不相同:文学化到什么程度,适合在什么情况下使用等等。这篇博文 Code is not literature 是一个有价值的材料,里面包含了 Knuth 本人的观点。在笔者看来,如今最为流行的风格是将完整的代码块作为内容的一部分插入到语段之间,其重点更偏向于文字。因此它天生适合分析报告、研究草稿一类的文档创作,因为代码编写顺序和研究思路大部分是重合的。
Donald Ervin Knuth 创造了第一个文学编程环境——WEB,在 1981 年引入了他的TeX排版系统。
至于 Literate Programming 与编写大段代码注释的区别,由于 CWEB 用户即使在国外也相对较少,因此笔者缺乏相关素材,留待日后补充。
Let us change our traditional attitude to the construction of programs: Instead of imagining that our main task is to instruct a computer what to do, let us concentrate rather on explaining to humans what we want the computer to do.
— Donald E. Knuth, Literate Programming, 1984
从流程上来说,统计研究是“搜集、整理、分析、表述数据,并推断对象的本质”,大部分统计研究流程与其代码均按照这个步骤组织,所以将它们写在一起是自然且方便的。另一方面,统计研究中很重要的一点是结果的可重复性,即 Reproducible Research。简单来讲,研究结果应该与数据和代码一起公布,并且不管谁运行它们,同样的条件下应该得到与自己相同的结果。
统计学定义来源于百度百科与 Sweave:打造一个可重复的统计研究流程
整理和分析信息与数据,并快速形成文档,在工作和研究中应用应该都很广泛。(笔者在两方面都了解不深)
如今数据分析用到的数据集越来越大,分析过程越加复杂,更加需要可重复性。
不过对于研究者而言,经常需要多次重复统计分析流程才能成功地得到结果,例如笔者就经常弄错数据表表头含义。要是每做出一个结果就截图留念、复制粘贴、错了重来,那得有多烦躁。我们需要的是一个能嵌入代码并动态生成图文报告的文档创作工具。
Sweave
在我们今天常用的 knitr 出现之前,Sweave 是第一个将 R 和 \(\LaTeX\) 结合在一起创建动态文档的工具。它于 2002 年诞生(或者更早?具体时间已不可考(ˉ﹃ˉ),连作者的主页也找不到了),作者 Friedrich Leisch 是 R 的核心开发者,他在 2002 年发表的论文中介绍了这个工具。
F. Leisch. Sweave: Dynamic generation of statistical reports using literate data analysis. In W. Härdle and B. Rönz, editors, Compstat 2002 — Proceedings in Computational Statistics, pages 575–580. Physika Verlag, Heidelberg, Germany, 2002. URL http://www.ci.tuwien.ac.at/~leisch/Sweave. ISBN 3-7908-1517-9.
Sweave 践行了 Literate Programming 的思想,使用 \(\LaTeX\) 编写文档(或者说控制格式?(●'◡'●))并将 R 代码块插入到 \(\LaTeX\) 文档中。其名称 Sweave 是 S + weave,也就是把文字和 S 语言(R 语言的前身)编织到一起。在编译文档过程中,Sweave 会抽取出文档中被特殊标记的 R 代码块并执行,然后将文档中的 R 代码块替换为其输出结果。从下面的例子中可以看出它的特点:
1 | \documentclass[a4paper]{article} |
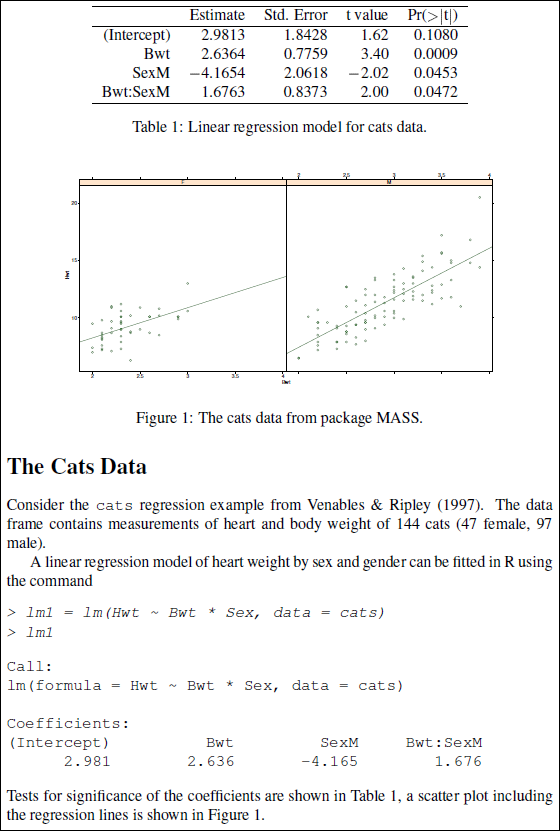
R 语言受到 S 语言和 Scheme 语言的影响发展而来,其中 S 语言的代码可以几乎不修改就在 R 环境下运行。S 语言的主要设计者 John M. Chambers 因其获得过 ACM 软件系统奖,之后还加入了 R 的核心开发团队。有关 R 语言的发展历史可以看看 R You Ready?——大数据时代下优雅、卓越的统计分析及绘图环境 一文。
谢益辉,郑冰 (2008). R 语言的历史背景、发展历程和现状. 1st China R Conference.
R 语言执行效率低确实是一个问题,不过 R 语言原生支持的算法采用 Fortran 科学计算库。
源代码中用<<>>=来标记代码块的开始,用@标记代码块的结束,其余部分则是文本与格式控制代码。很明显 Sweave 与 NoWEB 一类 Tex 生态的文学编程语言(WEB、CWEB 等)联系太过紧密,均采用 \(\TeX\) 写文档,或许这也是 Knuth 老爷子的巨大影响的一部分。不过与 \(\TeX\) 的关系也使得 Sweave 具有“先天缺陷”,因为 \(\TeX\) 不是随随便便就能精通的。由于老师要求,笔者不情不愿地使用 \(\LaTeX\) 写过作业报告,期间不是纠结于特殊字符怎么输入,就是头疼图片飘来飘去的问题……很难想象作者在写作时如果总是纠结一些排版问题,怎么有连贯的思路并专心地写作。尽管之后出现了像 LyX 之类简化 TeX 文档编写的优秀工具(集成了 Sweave),学习门槛高、用户基数少也依旧是 Sweave 的缺陷。
Knuth 大神当年不满意出版社的排版质量,为了将他的著作《计算机程序设计艺术》(The Art of Computer Programming,TAOCP)排版得更好看,他写出了 \(\TeX\) 排版系统。大概是对 \(\TeX\) 非常自信,Knuth 不仅将 \(\TeX\) 的版本号按照圆周率的小数位递进,还宣布从 1.28 美元开始,每发现一个Bug,奖金就会翻倍。奖金以支票形式发放,上面附有 Knuth 老爷子的签名,极具收藏价值(・∀・(・∀・(・∀・*)。
\(\TeX\) 把琐碎至极的排版细节一股脑展示给用户,好处是表现稳定,定制化程度高,缺点是每位用户得成为一名排版领域的专家。
knitr & rmarkdown
如果 Sweave 晚一点出现情况会如何呢?
2004 年 John Gruber 和 Aaron Swartz 合作创造了 Markdown 标记语言,它使用 HTML 作为输出格式的特点简直太符合时代的发展趋势。不过最重要的是它及其容易理解,不需要专门学习也能够连蒙带猜地理解;并且 Markdown 的语法是及其有限的,你能够在有限的时间内完完全全地精通它。这无疑给广大 LaTeX 苦手们带来了福音,在排版与内容创作之间找到了一个平衡点。
毫无疑问,Sweave 是伟大的作品。遗憾的是,Sweave 没有搭上 Markdown 的快车,但谢益辉(Yihui Xie)受 Sweave 启发,在 2012 年开发出 knitr 这一个功能强大的通用文学编程引擎。之所以说是“通用的”,是因为它支持使用 \(\LaTeX\)、HTML、Markdown 等标记语言撰写文本,使用 R、Python、C++ 等编程语言,覆盖了大多数流行的文学编程技术。而被称为“引擎”则是由于 knitr 的主要工作是转换,就像将汽油转换为汽车前进的动力,knitr 使用 Language Engine 将源文档中的代码块转换为对应的输出(文字或图像),替换源文档中的代码块,形成对应格式的标记语言文档。例如,假设使用 R Markdown 编写 .Rmd 文档,嵌入 R 语言代码块,则经过 knitr 处理后,我们的源文档就转变为正常的 .md 文档,不包含特殊标记的代码块。
graph LR A[.Rmd] -->|knitr|B[.md]
在这里需要特别说明一下。“R Markdown”作为一种文档格式第一次在 2012 年的 knitr 中引入,指的是在 markdown 中嵌入了 R 代码的文档格式。而在 2014 年,Allaire, Xie, McPherson, et al. 在 knitr 和 pandoc(不属于 R 生态圈)的基础上开发出了 rmarkdown 扩展包,它专注于使用 R 和 markdown 进行交互式的、可重复的数据研究。与 knitr 专注于做一个“透明的引擎”不同,rmarkdown 与很多扩展包相配合做出了很棒的应用,具体可见 R Markdown Gallery。如今,rmarkdown 和它背后的 knitr 一起发展和支撑着这个文档创作生态,一般也用 R Markdown 来表示。
这是
rmarkdown的logo,设计感和配色真好看(●'◡'●)b。不得不说 Hadley 一行人给 R 的生态带来了独特的活力。
Dynamic Documents with R and knitr 2nd Edition. Yihui Xie, 2013
Allaire, JJ, Yihui Xie, Jonathan McPherson, Javier Luraschi, Kevin Ushey, Aron Atkins, Hadley Wickham, Joe Cheng, Winston Chang, and Richard Iannone. 2021. Rmarkdown: Dynamic Documents for r. https://CRAN.R-project.org/package=rmarkdown.
本来应该说说
pandoc的厉害之处,它简直是标记文档领域的“金手指”,能够完成包含但不仅限于 Markdown、reStructureText、MS Word、MS PowerPoint、Jupyter Notebook、HTML、PDF、LaTeX、Wiki、EPUB 等文档的相互转换。但似乎写了太多考古的内容。。。这里就打住不说了。
rmarkdown 的主要作者 Allaire 也是我们使用的 RStudio IDE 的创造者以及 RStudio 公司的创立者和 CEO。因此使用 RStudio IDE 能够为 R Markdown 的使用者带来不少捷径。由于 RStudio 公司拥有像 Allaire、Hadley 和 Yihui Xie 等拥有巨大社区影响力的开发者,对于 R Package 开发生态和著名数据分析拓展包 tidyverse 拥有巨大影响力,因此很多社区成员担心该公司在盈利与开源的权衡中给予社区巨大的压力。不过 RStudio 在 2020 年改变了公司结构,使得从法律上允许公司在决策时考虑 R 社区的需求成为可能。
Hadley Wickham,
tidyverse扩展包的主要作者,R for Data Science 的作者,RStudio 首席工程师。他对于 R Markdown 生态亦有很多贡献,但在本文中不加详述。
bookdown
接下来让我们进入正题(😄~),bookdown 就是之前所述的 R Markdown 文档创作生态中的一员,它主要解决的问题是:
- 能够从
.Rmd文件一键生成多种格式的书籍,包括 PDF、HTML、EPUB、MS Word 等; - 可以将书的源文档拆分为多个
.Rmd进行管理,避免在较大的项目中管理单个文件; - 使
.Rmd文档可以支持公式、定理,以及图/表/章节/公式的自动编号和交叉引用; - 支持附录、文献引用等编写书籍(或论文!)的功能;
- 输出的 HTML 书籍默认使用 GitBook 样式,优雅中展现专业(*^_^*);
有了之前的考古,我们对于 bookdown 的定位就很清楚了。它是基于 rmarkdown(因此也依赖 knitr) 的文档组织与生成工具,组织体现在它对于写书这样一个大项目的多文件支持,生成指的是它专精于在线于印刷格式的书籍的生成,多使用 GitBook 作为样式。因此在撰写您的大作的流程中,bookdown 的存在感主要在项目配置、调试以及生成书籍中,作者接触最多的依旧是 rmarkdown 的使用。
有了上述特点,
bookdown的使用就不应局限于书本了。课程讲义、论文、笔记等都可以使用它。
依旧是好看的六边形logo。
下面进入主要操作流程:
本节内容关注大致的工作流程,因此不讲述太多的配置细节和 R Markdown 语法。
启动与项目结构
推荐使用 RStudio IDE 建立一个新项目,会自动生成必要的项目文件:New Project -> New Dictionary -> Book project using bookdown -> 选择项目名称和所在的目录。它会以项目名作为名称在选择的目录中新建一个文件夹,初始项目文件如下:
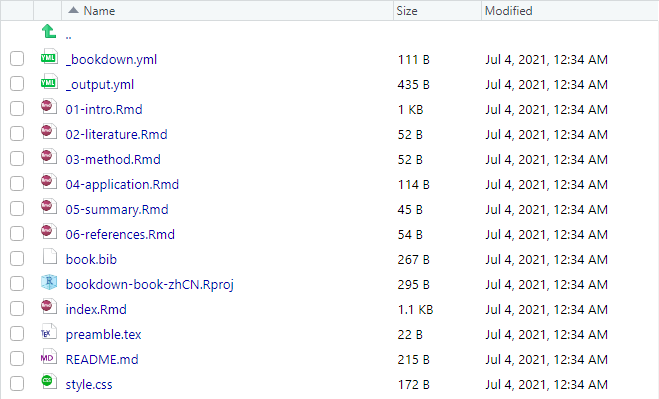
这个时候可以点击
index.Rmd,点击Build选项卡中的Build Book看看效果。
*.Rmd:包含所有书的内容。index.Rmd是书本的“主页”,开头包含 YAML 元数据(这属于pandoc风格),可以用来写序言、阅读指导、致谢等内容,其余文件包含各章节内容,不包含开头的 YAML 元数据,以两位数字作为编号标记各章节顺序;README.md:开源项目的项目说明文件;book.bib:记录参考文献的文件,属于 TeX 这一系统内的功能特点;(这也暗示我们可以在 Rmd 文档中使用 TeX 命令)_bookdown.yml:允许使用 YAML 来覆盖index.Rmd中的元数据,改变文档编译的行为,例如更改文档编译的顺序。_output.yml:用于指定书籍的输出格式。当然可以写在index.Rmd中,但把内容和格式控制分离难道不是个很好的想法吗?preamble.tex&style.css:用来调整书籍输出的外观,preamble.tex针对的是 PDF 格式,style.css针对的是 HTML 格式。
事实上,最少只需要一个
index.Rmd文件即可使用bookdown编译为书籍。
设置书籍的元数据
比如书名、作者、发布日期等信息,它们都在 index.Rmd 开头的 YAML 块中进行设置:
1 | --- |
其中 site 这一项较难理解。笔者认为该项设置的内容和它的名称一样,是网站生成方式,一般这一项的内容为 bookdown::bookdown_site,表示生成的网站是 bookdown 书籍网站,之所以用 site 可能是考虑到可扩展性。另外,可以使用以下 bookdown 函数来生成书籍:
1 | bookdown::render_book("foo.Rmd", "bookdown::gitbook") |
但如果设置 site 字段,则可以将控制格式的 bookdown::gitbook 等函数及其参数放在 output 字段中,或者是 _output.yml 文件中管理,如下所示:
1 | --- |
之后便可以使用 Build Book 按钮来一键生成书籍。
章节结构
一般来说,每个 .Rmd 文件都单独作为一章进行编写,bookdown 按照文件名的顺序进行编译(index.Rmd 除外),因此一般使用 00-<名称>.Rmd、01-<名称>.Rmd 的命名方式来管理各章的源文档。
一般除了 index.Rmd 以外的各章均以一级标题开头,如果需要在文中引用该章,可以给这一章加一个标签,格式为 {#<标签名称>}。
1 | # 章节结构 {#chapter_structure} |
另外,内容相近的章节可以组成一个部分,通过使用一级标题、(PART) 和 {-} 来完成定义:
02-章节结构.Rmd1
2
3# (PART) 测试部分-1 {-}
# 章节结构03-交叉引用.Rmd1
2
3# (PART) 测试部分 {-}
# 交叉引用
其中 (PART) 表示这是书籍的一部分,内含一组章节;一级标题 # 定义该部分题目的展示格式;{-} 表示这一个标题不是一个章节,不参与章节标号。
另外可以定义书籍的附录(APPENDIX),附录部分的章节按照 A.1、A.2、B.1 的顺序尽心标号。
1 | # (APPENDIX) 附录 {-} |
交叉引用
- 方程
直接使用如下格式的 latex 语句,注意使用 equation 环境。(\#eq:<标签名称>) 定义该方程的标签,引用时使用 \@ref(eq:<标签名称>)
1 | \begin{equation} |
- 定理
通过 \@ref(thm:<定理标签>) 来引用。
1 | ```{theorem, <定理标签>, name="定理名称"} |
文献引用
文档中的格式为:[@<引用名称>],.bib 文件中引用项的格式和 LaTeX 中相同。
书本编译
一般通过在 index.Rmd 中设置 site: bookdown::bookdown_site 来使用 Build Book 按钮进行编译。编译结果默认保存在 _book 目录中,可以在 _bookdown.yml 中进行更改。
如果不想每次更改后在手动编译全书,可以使用 RStudio Addins "Preview Book" 或者 bookdown::serve_book() 启动一个本地服务器,访问 http://127.0.0.1:4321 即可。
参考资料
R Markdown: The Definitive Guuide 适合作为一本参考书,而不是教材。它的重心在于 rmarkdown 的各种输出格式,例如HTML、PDF、Word、Presentation、Dashboard;另外还提供了其他几个 R Markdown 扩展包的详细内容,例如 bookdown、blogdown、rticles、shiny。
R Markdown Cookbook 适合作为教材,它提供了更精简且更有代表性的示例来展示更加实用的内容。另外,和其他众多 *** cookbook 一样,这本书的内容是按照问题来组织的,它们来自 Stack Overflow 以及其它网站的热门帖子。
按照我的经验(2021年7月以前),遇到了 R 相关的问题,第一个考虑是 R 自带的 Manual(功能性问题,速度快),其次是 GitHub Issues 和 Stack Overflow(奇怪的Bug,有针对性),然后是翻阅上述书籍查找答案(全面,边思考边查阅)。而最浪费时间的就是 CSDN 一类的中文博客网站,它们除了浏览速度快以外几乎找不到准确且新鲜出炉的解决方案。
其实要论中文网站的话,统计之都上的内容最为优质。主站内容偏重于介绍和应用,论坛内容多为问答。不过该网站的速度略慢,习惯了短视频的人们需要有一定耐心。(P.S.难受的是,对于笔者遇到的问题,简单的用不着该网站,困难的找不到确切的方法 ╮(╯▽╰)╭。)
😄换句话说,多看英文 (●ˇ∀ˇ●),R 语言的中文生态还需要我们培养。
小建议01:由于
rmarkdown以及knitr对其的严重依赖性,很多文档编译设置、问题都可以通过 pandoc 文档解决(这就是你的文档零零散散的理由?(⓿_⓿))。对于不愿意 Hacking 的使用者,面对排版上的问题,而又无法通过 R Markdown 的生态解决,那么最好的解决方法是减少对于排版的“严格”要求,以免和笔者一样陷入搜索文档-翻阅文档的痛苦循环中。
小建议02:同样由于
knitr以及rmarkdown对于pandoc的重度依赖,且没有封装足够多的 pandoc API,因此想要深度定制化,可能得会 LaTeX、HTML、CSS 等一系列技术,对于笔者来说比较复杂。。。
小建议03:如果想把文档输出为 PDF 格式,需要有 TeX 环境。这里推荐谢益辉大神的
TinyTex包,在 R 中可以一键安装 TeX 环境,依赖宏包的安装不容易出问题。国内下载宏包较慢,需要等待1-2小时,笔者还没来得及找解决办法。
小建议04:所有文档保存为 UTF-8 编码格式!!!Linux 和 Mac OS 用户应该可以忽略这一点(说的就是你,Windows)。UTF-8 对不同字符具有良好的跨平台支持,可以解决许多无谓的乱码问题。