神经网络学习_实验
神经网络学习_实验
经过数学公式的洗礼,是时候上手看看我们的代码效果如何了。
数据集
MNIST,下载地址:http://yann.lecun.com/exdb/mnist/
小数据集
- mnist_train_100.csv:100个训练数据
- mnist_test_10.csv:10个测试数据
完整数据集
- mnist_train.csv:60000个训练数据
- mnist_test.csv:10000个测试数据
实验代码
首先我们设定常量参数 input_nodes 和 output_nodes。输入神经元数量受到数据格式的限制,由于数据集中每条记录都是一张 28x28 的灰度图,因此输入每个像素的灰度值需要 784 个神经元。而神经网络输出的格式更灵活,不过这里我们设定为 10 个神经元,分别代表阿拉伯数字 0~9。
还可以使用 5 个神经元输出,用来代表 0~9 的二进制位。不过这样的话,1层隐藏层足够吗?
可变参数就是隐藏层神经元个数、学习率和训练世代数。
训练世代数,指对于一个数据集,重复多次地进行训练。值得注意的是,我们使用的梯度下降法只走了一步,也就是在下山过程中,朝着最陡峭的方向走了有限的一步,这当然几乎不能达到极小值点。因此我们多训练几个世代,让它有更多的机会向下走,一定程度上有助于收敛。
1 | if __name__ == "__main__": |
Learning Rate
实验数据
| No. | Hidden Nodes | Learning Rate | epochs | Score |
|---|---|---|---|---|
| 1 | 5 | 0.01 | 5 | 0.4836 |
| 2 | 5 | 0.05 | 5 | 0.6688 |
| 3 | 5 | 0.08 | 5 | 0.8011 |
| 4 | 5 | 0.1 | 5 | 0.7691 |
| 5 | 5 | 0.2 | 5 | 0.7557 |
| 6 | 5 | 0.3 | 5 | 0.6935 |
| 7 | 5 | 0.4 | 5 | 0.6076 |
| 8 | 5 | 0.5 | 5 | 0.5803 |
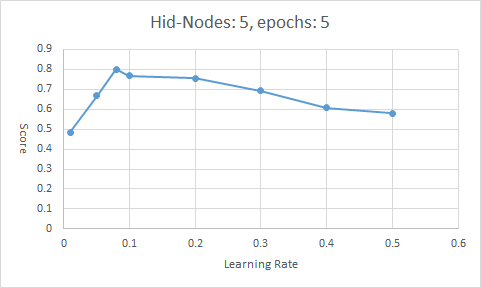
随着学习率的增大,模型的表现先升高再降低,峰值出现在 \([0.08,0.1]\) 之间。过高和过低的学习率都会造成模型的正确率下降,可以从 神经网络学习_反向传播与梯度下降(1)一文中得到解释。
Hidden_Nodes
实验数据
| No. | Hidden Nodes | Learning Rate | epochs | Score |
|---|---|---|---|---|
| 1 | 5 | 0.1 | 5 | 0.7691 |
| 2 | 10 | 0.1 | 5 | 0.8905 |
| 3 | 50 | 0.1 | 5 | 0.9582 |
| 4 | 100 | 0.1 | 5 | 0.9666 |
| 5 | 200 | 0.1 | 5 | 0.9739 |
| 6 | 300 | 0.1 | 5 | 0.9741 |
| 7 | 500 | 0.1 | 5 | 0.9747 |
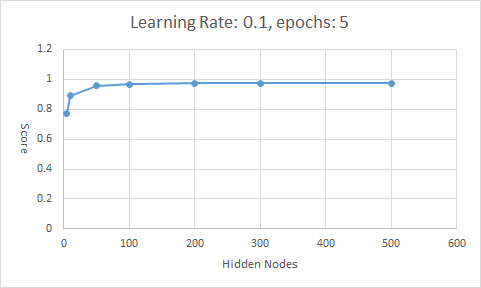
随着隐藏层节点数量的增多,模型的正确率越来越好,正确率上升的速度逐渐减慢。若将权重矩阵视作模型储存的知识,那么10个结点能储存的知识显然比100个结点储存的知识要少。但是训练时隐藏层结点数量越多,计算起来越慢,且正确率的提升效果越差。
Epochs
实验数据
| No. | Hidden Nodes | Learning Rate | epochs | Score |
|---|---|---|---|---|
| 1 | 10 | 0.1 | 1 | 0.8664 |
| 2 | 10 | 0.1 | 3 | 0.8781 |
| 3 | 10 | 0.1 | 5 | 0.8905 |
| 4 | 10 | 0.1 | 7 | 0.8872 |
| 5 | 10 | 0.1 | 10 | 0.9003 |
| 6 | 10 | 0.1 | 15 | 0.9084 |
| 7 | 10 | 0.1 | 20 | 0.9014 |
| 8 | 10 | 0.1 | 25 | 0.9011 |
| 9 | 10 | 0.1 | 30 | 0.8962 |
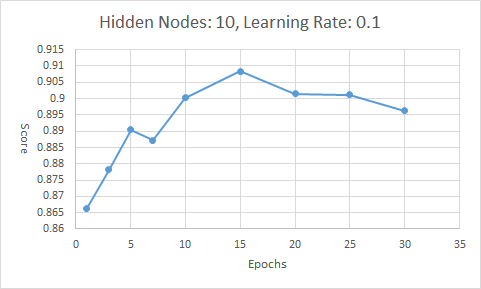
由于对每一个样本进行训练时,梯度下降法只走一步,因此多轮训练能够给予更多的梯度下降的机会。但是过高或过低的训练世代数都会使得模型表现差,这是因为训练少了难以下降到局部最优,训练多了模型会学习过多的训练样本的特征,对于没有训练过的样本的表现不好。
注意
由于权重矩阵初始值是随机得到的的,因此每次对于同样的样本训练,得到的正确率也不一定相同。另外笔者发现,当隐藏层节点数量较少时(例如5个),同样的样本和参数进行训练,得到的正确率极差较大(约为 \([0,0.3]\))。
横向对比
使用如下参数训练模型:
- Hidden_Nodes = 200
- epochs = 5;
- Learning_Rate = 0.09
模型在测试集上的正确率为 0.9760。
与 THE MNIST DATABASEof handwritten digits 上的记录进行对比,在 Neutral Nets 一栏也可以排在中等偏上水平。并且此次训练只使用了2层神经网络(输入层未计入)和200个隐藏层节点,训练了5个世代。
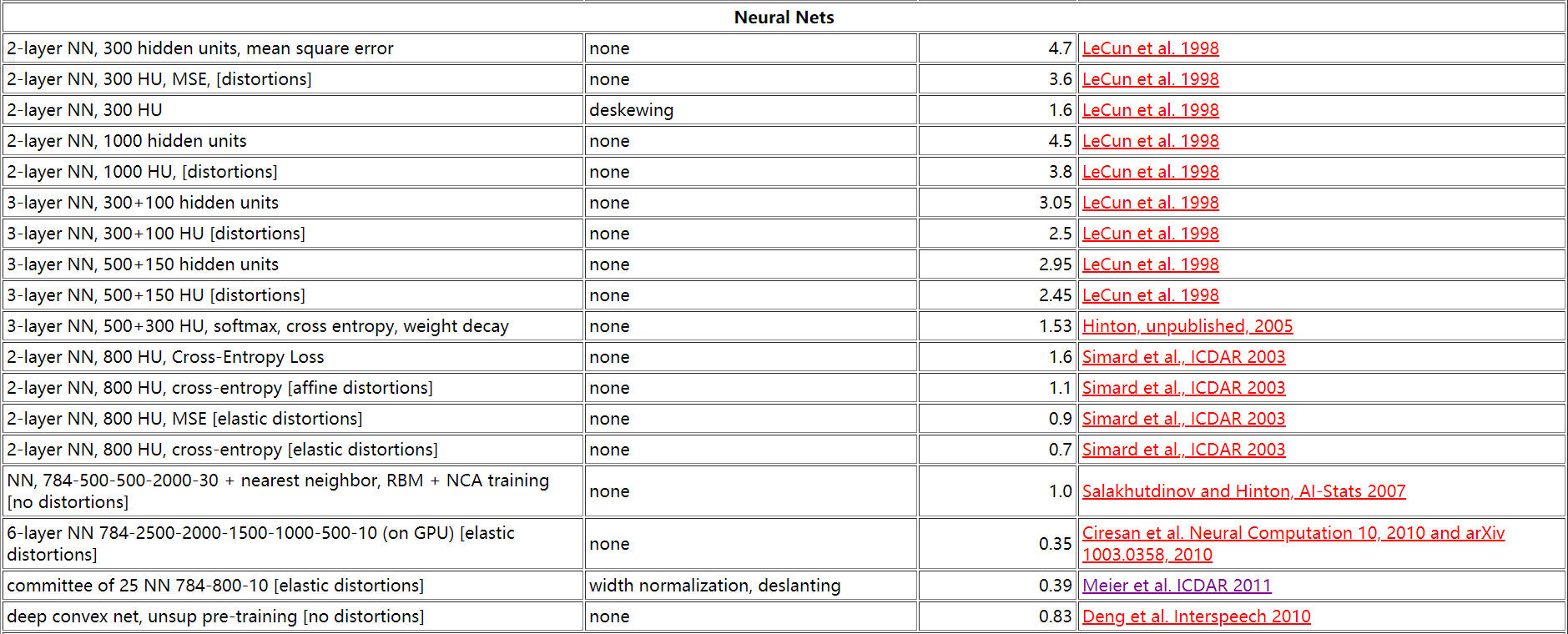
上图左起第3列均为错误率(%)