Python进阶
Python进阶
目录
[TOC]
Python数据模型
数据模型 ?:对Python框架的描述,规范了语言自身构建模块的接口。
一致性:任何获取对象长度的方法都是 len()。 Pythonic
如何达到一致性的呢?
对任何对象 obj,在使用 len(obj) 时,Python解释器会调用特殊方法,即 obj._len_()。只需要重写 __len__ 方法,就能够使用通用的 len() 来获取对象长度。
Magic Method
特殊方法。
__getitem & __len
len(obj)andobj.__len__()obj[key]andobj.__getitem__(key)
Example 1:Card
1 | import collections |
collections.namedtuple(
, [ 用于构建只有少数属性而没有方法的对象。])
1 | # 牌堆类 |
''' French playing cards (jeu de cartes) are cards that use the French suits of trèfles (clovers or clubs♣), carreaux (tiles or diamonds♦), cœurs (hearts♥), and piques (pikes or spades♠). Each suit contains three face cards; the valet (knave or jack), the dame (lady or queen), and the roi (king). '''
可以看出,magic method有以下好处:
1、对于任意类,直接使用 magic method 就可以完成类的标准操作,不需要考虑获取长度是.length()还是.size()等形式。
2、可以使用像 random 这样的内置库达到定义的类的标准操作,不需要重写方法。
由于 class deck 中 __getitem__ 方法将操作 [] 的对象定义为 self._cards,因此__getitem__方法对应的操作 [] 能够在 class deck 上实现纸牌的切片,实际上是 self._cards 的切片。
1 | # deck的切片 |
同样,__getitem__方法也导致 class deck 可迭代(__iter__)
1 | # deck的迭代和反向迭代 |
如何实现排序?
按照点数:min = 2, max = A,按照花色:spades > hearts > diamonds > clubs
1 | # 定义纸牌的位置权重 |
洗牌功能使用
__setitem__实现。
通过实现__len__、__getitem__,class FrenchDeck就几乎等同于Python数据类型:列表,能够实现列表的排序、切片等操作。
Attention!
实现如此简便的纸牌类的关键有两个:
1、唯一内置隐藏属性对应着 List 这一数据类型,使得具有形式:deck = FrenchDeck()、deck[:3],简洁;
2、重载 magic method 使得类的操作具有普遍性,Pathonic。
magic method在除元编程以外的环境下很少用到,这是Python解释器调用的;
元编程:使用代码生成代码
对于__len__来说,CPython中直接读取 PyVarObject (可变内存对象)的C语言结构体的 ob_size属性,更快;
运算符重载
Example 2:Vector
1 | class Vector: |
Vector类重定义了__add__、__mul__、__bool__、__abs__、__repr__内置方法,使得利用运算符+的向量的加法、利用*的向量的数乘、利用abs()的向量取模符合定义,并且可以利用bool()判断向量是否为非零向量。
Attention!
- 使用
__repr__表达对象:
1 | # 一般直接输出对象是这样的: |

“Difference between str and repr in Python”(http://stackoverflow.com/questions/1436703/differencebetween-str-and-repr-in-python)是 Stack Overflow 上的一个问题,Python 程序员 Alex Martelli 和 Martijn Pieters 的回答很精彩。
- 使用
__bool__进行真值判断:
1 | return bool(self.x or self.y) |
比起使用以下语句更加高效
1 | return bool(abs(self)) |
需要注意的是,我们定义的对象总被认为是 True,除非该对象重载了 __bool__ 或 __len__。
调用顺序:__bool__ -> __len__
Magic Method List
非运算符魔术方法:
| 类别 | 方法名 |
|---|---|
| 字符串/字节序列表示形式 | __repr__、 __str__、 __format__、 __byte__ |
| 数值转换 | __abs__、 __bool__、 __complex__、 __int__、 __format__、 __hash__、 __index__ |
| 集合模拟 | __len__、 __getitem__、 __setitem__、 __delitem__、 __comtains__ |
| 迭代枚举 | __iter__、 __reversed__、 __next__ |
| 可调用模拟 | __call__ |
| 上下文管理 | __enter__、 __exit__ |
| 实例创建和销毁 | __new__、 __init__ 、 __del__ |
| 属性管理 | __getattr__、 __getattribute__、 __setattr__、 __delattr__、 __dir__ |
| 属性描述符 | __get__、 __set__、 __delete__ |
| 跟类相关的服务 | __prepare__、 __instancecheck__、 __subcalsscheck__ |
运算符相关特殊方法:
| 类别 | 方法名及对应运算符 |
|---|---|
| 一元运算符 | __neg__-、__pos__+、__abs__ |
| 比较运算符 | __lt__<、__le__<=、__eq__==、__ne__!=、__gt__>、__ge__>= |
| 算术运算符 | __add__+、__sub__-、__mul__*、__truediv__/、__floordiv__//、 __mod__%、__divmod__divmod()、__pow__**、__round__round() |
| 反向算术运算符 | __radd__、__rsub__、__rmul__、__rtruediv__、__rfloordiv__、__rmod__、__rdivmod__、__rpow__ |
| 增量赋值算术运算符 | __iadd__、__isub__、__imul__、__itruediv__、__ifloordiv__<br 、__imod__、__ipow__ |
| 位运算符 | __invert__~、__lshift__<<、__rshift__>>、__and__&、__or__ |
| 反向位运算符 | __rlshift__、__rrshift__、__rand__、__rxor__、__ror__ |
| 增量赋值位运算符 | __ilshift__、__irshift__、__iand__、__ixor__、__ior__ |
Advantages
为什么要使用魔术方法?
从FrenchDeck类的示例可以知道,Magic Method使得自定义的类(数据模型,以特有方式构建、储存数据)能够在各种操作方法上表现得像内置数据类型一般,这种共同性是Python简洁明了、表达力强的原因之一。
Python语言参考手册,“Data Model”:https://docs.python.org/3/reference/datamodel.html
Martelli's Stack Overflow:http://stackoverflow.com/users/95810/alexmartelli
平衡的艺术
为什么将 len() 作为一个特殊方法?如果 x 是内置类型,那么 len(x) 会直接从C结构体中提取属性,不调用方法,速度非常快。如果不是内置类型,则使用 __len__。因此 len() 作为特殊方法在内置类型的效率和语言的一致性上达成平衡。
数据结构
序列构成的数组
容器序列:储存对象的引用,可以存放多种类型的数据。
扁平序列:储存值,只能存放一种类型的数据。
可变序列:list、bytearray、memoryview、…
不可变序列:tuple 、str、bytes
列表推导式
list comprehension (listcomps)
1 | [ord(s) for s in words if ord(s) > 20] |
在
[]、{}、()中,换行会被忽略。
也可以用 map filter 完成:
1 | list(filter(lambda x:x > 20, map(ord, words))) |
哪一个效率更高?
通过以下程序可以粗略估计,列表推导式效率更高。
1 | import timeit |
输出:
1 | listcomp : 0.020 0.020 0.021 0.020 0.020 |
生成器表达式
generator comprehension (gencomps)
生成器 generator,逐个产出元素,能够节省内存。方便初始化元组、数组等序列。
圆括号
(),作为参数时省略
1 | (ord(s) for s in words) |
元组拆包
元组重要的特点是“不可变”。
但是元组不仅储存了元素的信息,还储存了元素的位置信息,适合记录数据。
元组拆包 tuple unpacking:
- 平行赋值
1 | lax_coordinates = (33.9425, -118.408056) |
*拆包可迭代对象
1 | t = (20, 8) |
*获取剩余元素
1 | a, b, *rest = (1, 2, 3, 4) |
%匹配元组元素
1 | traveler_ids = [('USA', '31195855'), ('BRA', 'CE342567'), ('ESP', 'XDA205856')] |
- 嵌套元组拆包
1 | a, b, (c, d) = (1, 2, (3, 4)) |
关于占位符
_:很多时候是一个很好的占位符,但是在国际化软件里,_也是gettext.gettext的常用别名。
具名元组
collections.namedtuple:构建带字段名的元组和一个有名字的类。
用元组作为数据的记录,还少了字段的命名。因此使用具名元组。
1 | card = collections.namedtuple('Card', ['rank', 'suit']) |
具名元组还具有一些专有属性:
1 | from collections import namedtuple |
_fields:字段名_make(iter):接受一个可迭代对象作为参数,构造具名元组_asdict():返回该实例的 collections.OrderedDict 形式。
序列切片
为什么切片会忽略最后一个元素?
1 | a = [1,2,3,4] |
- 方便知道切片中有多少元素
- 快速计算切片长度(末尾 - 起始)
- 用一个下标分为两部分
[:a] [a:]
切片对象 slice object
从 a 到 b,以 c 为步长进行切片。
1 | A[a:b:c] |
1 | a:b:c => slice(a, b, c) |
多维切片
对于矩阵等二维数组,可以使用多维切片:
1 | [m:n, k:l] |
实质上是 __getitem__((m,n), (k,l))
省略号
1 | ... |
1 | a[i, ...] => a[i, :, :, :] |
切片实质上是对于原来序列中一部分元素的引用,修改切片会修改原序列。
序列的+和*
初始化一个由列表组成的列表?
1 | a = [[]] * 3 |
[[]] * n 实质上创建了 n 个指向同一个列表的引用。
该如何修改?
1 | a = [[] for i in range(3)] |
每次迭代都产生了新的列表实例。
序列的增量赋值
1 | a += b |
实质上是 __iadd__ 和 __imul__ 方法在起作用,如果第一个操作对象不具有这两个方法,那么就会调用 __add__ 和 __mul__。
Attention_1
__iadd__ 和 __imul__ 不改变变量的地址,而调用 __add__ 和 __mul__ 实质上执行了:
1 | a = a + b |
有一个赋值语句,将新的值赋给了新的对象,改变了 a 的地址。
Attention_2
1 | a = (1, 2, [3, 4]) |
会发生什么?
1 | Traceback (most recent call last): |
结果是既抛出了错误,又改变了不可变的元组!
查看字节码如下:
1 | dis.dis("a[2] += [5, 6]") |
STORE_SUBSCR: a[2] = TOS 赋值操作抛出错误。
list.sort 与 sroted
区别:list.sort 为原址排序,不产生新的列表对象,返回 None;而 sorted 返回新的排好序的列表。
连贯接口 fluent interface
参数:
reverse:默认为False,若为True则降序输出key:只有一个参数的函数,用于对序列中的每一个元素产生一个对比关键字。使用str.lower实现忽略大小写的排序,使用len实现根据字符串长度进行的排序……
算法使用的是 Timsort,会根据原始数据的顺序特点交替使用插入排序和归并排序。作者为 Tim Peters (Timbot),也是 Python之禅 的作者(
import this)
bisect 操作已排好序的序列
bisect:二分,对半。
bisect、insort:利用二分查找算法在有序序列中查找或插入元素。
1 | # 在 haystack(干草垛)种搜索 needle(针)的位置 |
结果满足:把 needle 插入该位置后,haystack 还能够保持升序,
1 | import bisect |
输出:
1 | PS > python37 .\bisect_test.py |
1 | PS n> python37 .\bisect_test.py left |
还可以通过两个元素互相对应的有序列表,将一个列表中的值排序到对应的区间内 bisect_left,再获取另一个列表中的对应值。
1 | def trans_grade(score, breakpoints=[60,70,80,90], grades="FDCBA"): |
bisect 将返回分数对应的第 i 个分数段,通过分数段序号取对应等级。
bisect = bisect_right:所有的haystack[:i]都小于等于 needle
bisect_left:所有的haystack[:i]都小于 needle,也就是遇上了相等元素,新元素放在前面
Attention!
str.format,参数作为一个元组传入,format string 中的{m:nX}表示:取参数元组中的第m个,字段宽度为n,按照数据类型X右对齐输出。
.join()接受一个序列类型,或者一个序列生成器。
sys.argv获取命令行参数。
列表不是首选时
列表背后存储的是 int、float 等对象,而数组 array 存储数字的字节表述。
如果需要频繁对序列进行先进先出操作,双端队列 deque 速度更快。
array 模块
1 | # 根据 类型码 和 初始值 创建存储为字节码的数组 |
需要注意的是,array.tofile 和 array.fromfile 用起来简单且快速,比从文本读入快多了。因为后者会调用 float 方法将每一行文字转换为浮点数。并且写入二进制文件 *.bin 时,占用的空间更少。不过, python3.4 之后,数组不支持就地排序,需要用 sorted。
memoryview
内存视图。在不复制内容的情况下操作同一个数组的不同切片。处理大型数据集合时很重要。
1 | # 创建 短整型有符号整数 数组 'h' |
‘h’ 占 2 个字节,’B’ 占 1 个字节,因此使用
memvoryview.cast('B')时,每个短整型有符号数字被划分为高位 + 低位。例如:-2的字节码划分为高位和低位就是 254、255。
NumPy 和 SciPy
另有笔记进行学习。
双端队列
普通列表通过 append 和 pop 模拟栈。
collections.deque 支持更快速、线程安全的队列类型。maxlen 参数指明队列容纳的元素个数。
rotate(n):将队列的右侧(n>0)n个元素移动到左侧,反之移动到右侧。1
2
3
4
5
6
7dq = collections.deque(range(10), maxlen = 10)
dq
deque([0, 1, 2, 3, 4, 5, 6, 7, 8, 9], maxlen=10)
dq.rotate(3)
deque([7, 8, 9, 0, 1, 2, 3, 4, 5, 6], maxlen=10)
dq.rotate(-4)
deque([1, 2, 3, 4, 5, 6, 7, 8, 9, 0], maxlen=10)appendleft:左侧添加元素,若队列已满则删除最右侧元素。1
2dq.appendleft(-1)
deque([-1, 1, 2, 3, 4, 5, 6, 7, 8, 9], maxlen=10)extend:将序列中的元素依次添加到右侧,挤出左侧元素。1
2dq.extend([11,22,33])
deque([3, 4, 5, 6, 7, 8, 9, 11, 22, 33], maxlen=10)extendleft:将序列中的元素依次添加到左侧,挤出右侧元素。1
2>>> dq.extendleft([44,55,66,77])
deque([77, 66, 55, 44, 3, 4, 5, 6, 7, 8], maxlen=10)
append 和 popleft 都是原子操作,也就说是 deque 可以在多线程程序中安全地当作先进先出的栈使用,而使用者不需要担心资源锁的问题。
其他队列
queue:同步类Queue、LifoQueue 和 PriorityQueue
multiproessing:进程通信用、JoinableQueue 用于任务管理
asyncio:包括前两者提供的 Queue,用于异步编程
heapq:堆队列、优先队列
字典与集合
高度依赖散列表。
泛映射类型
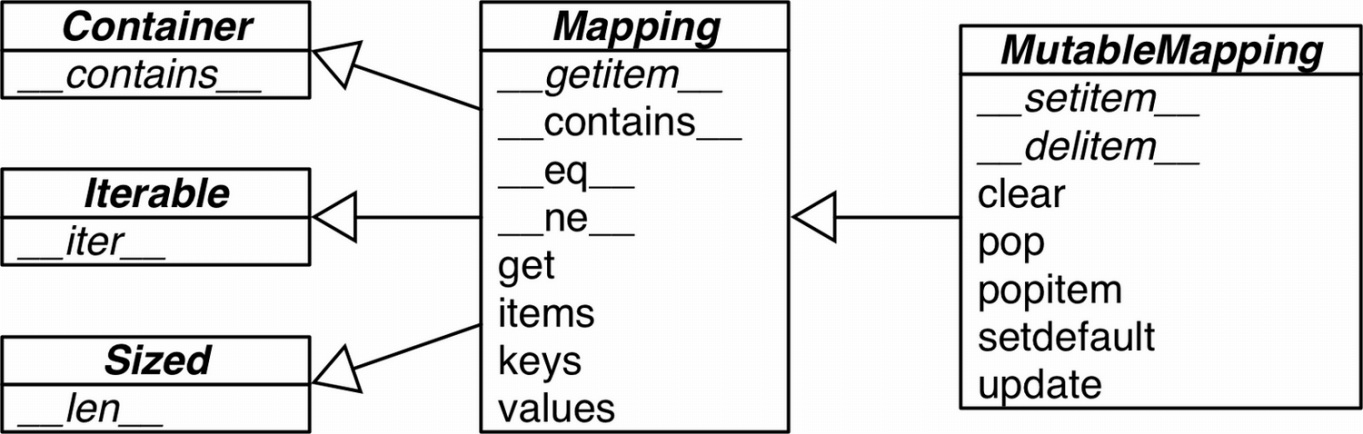
collections.abc 中有 Mapping 和 MutableMapping 两个抽象基类,为 dict 和其他类似的类型定义了形式接口。
dict 继承自 object 对象,使用 __mro__ 判断方法解析顺序,可以知道 dict 的基类:
1 | dict.__mro__ |
但是抽象基类能够注册虚拟子类。在 import collections 时,执行了 MutableMapping.register(),将 dict 注册成了自己的虚拟子类,因此:
1 | from collections.abc import MutableMapping |
而Python代码版本的内置类型 dict 则实现了C代码版本的 dict 的所有接口,可以构建自己的映射类型:
1 | >> from collections import UserDict |
字典推导
1 | DIAL_CODES = [ |
setdefault 处理找不到的 key
快速失败理念:快速抛出异常。
d[k] 找不到正确的 key 的时候,Python会抛出异常。可以使用 d.get(k, default) 来给找不到的 key 一个默认的返回值。
1 | d = {1:2, 3:4} |
但是这样无法很好地更新或者添加键值对。
下面的例子从文本文件中统计各个单词出现的位置(开头字母的行号和列号)。将新出现的键放入字典时,涉及到了两次查询和依次列表 append 操作,代码表达力不强。
1 | import sys |
使用 setdefault 有更好的写法:
1 | my_dict.setdefault(key, []).append(new_value) |
defaultdict 为找不到的 key 创建默认值
1 | import collecitons |
default_factory只在__getitem__里调用,只能使用my_dict[key],而使用my_dict.get(key)会返回None。
特殊方法 __missing__
__missing__ 在映射类型找不到 key 的时候发挥作用,基类dict没有定义该方法。与 default_factory 相同,__missing__ 只会在 __getitem__ 中调用,对于 get 或 __contains__ 方法没有影响。
1 | class StrKeyDict0(dict): |
上述代码定义了一个用字符串作为键值的字典类 StrKeyDict0。增加了 __missing__ 方法,重写了 get 方法和 __contains__ 方法。
当使用 d[key](也即 d.__getitem__(key))时,key 找不到的情况有两种:
key是字符串但不在字典的键中;key不是字符串。
上述情况都会调用 __missing__ 方法,因此在 __missing__ 方法中,当 key 不是字符串时,转化为字符串后再进行 __getitem__ 调用。
注意,
isinstance判断是必须的,如果不判断,则产生无限递归。> graph LR > subgraph "isinstance" > C["__getitem__(key)"] --"Failed"--> D["__missing__(key)"] > D --"str"--> E["Raise ERROR"] > D --"NO str"--> F["__getitem__(str(key))"] > end > subgraph "NO isinstance" > A["__getitem__(key)"] --"Failed"--> B["__missing__(key)"] > B --"Call"--> A > end >
上述代码中,当使用 get() 方法时,查找工作实际上被委托给了 __getitem__ 方法,而 __getitem__ 又会通过 __missing__ 方法多给一次机会。
当使用 __contains__ 方法时,若传入的 key 不是字符串,那么会转化为字符串再加以判断。
不使用
k in d,反而使用k in d.keys(),这是因为前者会造成__contains__的递归调用。> graph LR > subgraph "k in d.keys()" > C["d.__contains__(key)"]--"return"--> D["k in d.keys()"] > D --"Call"--> E["d.keys().__contains__(keys)"] > end > subgraph "k in d" > A["d.__contains__(key)"]--"return"--> B["k in d"] > B --"Call"--> A > end >
Attention_1
1 | k in my_dict.keys() |
由于使用了 “Dictionary View Object”,上述查询在 Python 3 中是很快速的。
my_dict.keys() 返回的不是像 Python 2 中的列表,而是一个“视图”,类似于一个集合。
字典的变种
OrderedDict
记录添加键的顺序。使用 popitem 方法默认删除并返回字典的最后一个元素;popitem(last = False) 删除第一个添加的元素。
Python 3 中,字典的键实质上是有序的,但是基类
dict的popitem没有last参数。
ChainMap
容纳多个不同的映射对象,在执行键的查找时,这些对象会逐个被查找,直到找到为止。
能够用它作为嵌套作用域的上下文:
1 | import builtins |
Counter
计数器,可用于文章的单词计数。每次更新一个键的时候都会增加对应的计数器。
可以使用 +、- 运算符合并记录。
most_common(n) 返回前 n 个计数最多的键和它的计数。
UserDict
Python 实现的基类 dict。用于被用户自定义的子类继承。
继承 UserDict
为什么不继承
dict?主要因为内置类型的某些实现走了捷径,继承后不得不自己重写某些方法。
UserDict 是 dict 的 Python 实现,其中他有一个叫做 data 的属性是 dict 的实例,用于最终储存数据。这样做引入了新的操作对象,避免了对自身的操作,也就不会造成方法的递归。
1 | import collections |
__contains__ 和 __setitem__ 都是在对 self.data 属性进行操作,从而避免了对 self 操作造成的递归问题。
继承关系:
graph LR A["StrKeyDict"] --> B["UserDict"] --> C["MutableMapping"] --> D["Mapping"]
两个继承而来的实用方法:
MutableMapping.update:利用传入的参数构造新的实例,背后使用的是 self[key] = value。
Mapping.get :基类 dict 中,__getitem__ 会调用 __missing__ 方法,而 get 不会。但是有时候,我们希望二者的行为是一致的,都会调用 __missing__ ,这就要求我们重写 get,把具体实现委托给 __getitem__。而 Mapping.get 方法就是按照这样的思路定义的,省去了我们重写的工作。
TransformDict
不可变的映射类型
映射类型都是可变的,但是有时候我们不希望用户能够修改一个映射。可以通过 types.MappingProxyType 产生一个只读的映射视图,用户不能修改映射视图,但是原映射修改后,它的映射视图也会自动改变。
1 | from types import MappingProxyType |
集合
set 或 frozenset
空集必须写成
set(),字面量则可以写成{1, 2}
基本操作:
| 示例 | 意义 |
|---|---|
a | b |
并集 |
a & b |
交集 |
a - b |
差集 |
a ^ b |
对称差集 |
集合推导
setcomps
新建一个 Latin-1 字符集合,该集合中的每个字符的 Unicode 名字里都有 “SIGN” 单词:
1 | from unicodedata import name |
Attention_1!
unicodedata.name:获取字符的名称
集合的操作
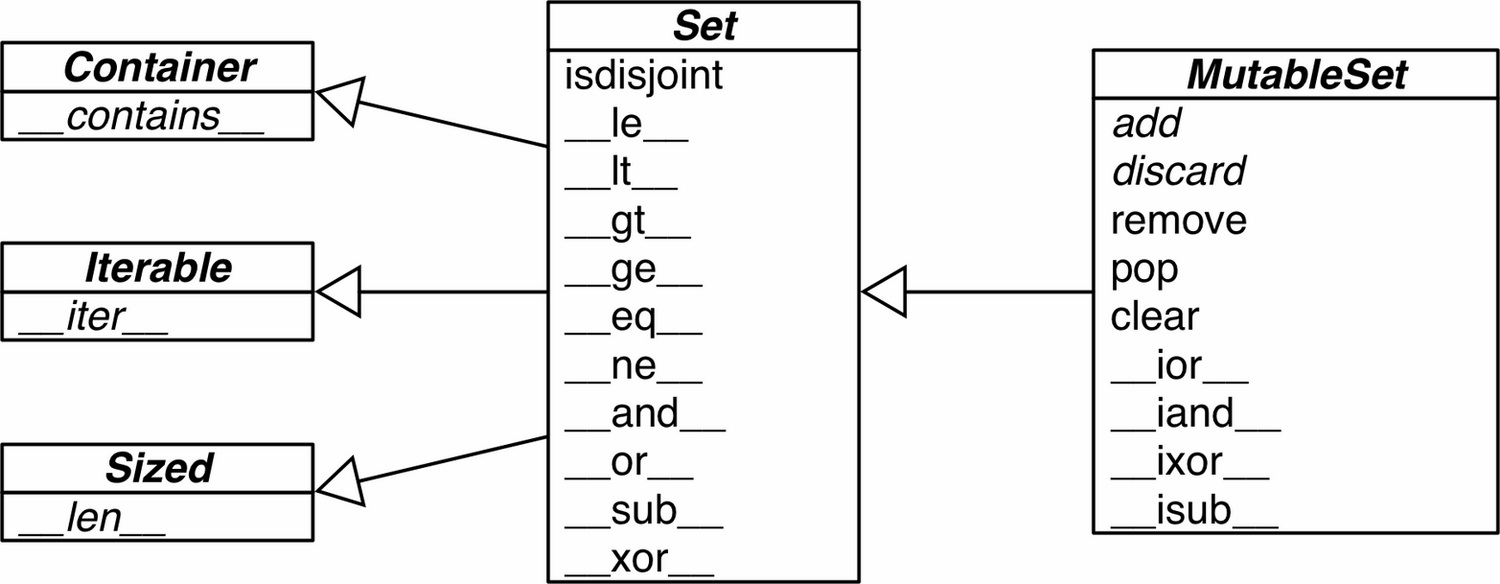
以交集运算为例:
s & z==s.__and__(z)z & s==s.__rand__(z)==s.intersecton(it, ...)s &= z==s.__iand__(z)==s.intersection_update(it, ...)
比较运算:用偏序关系定义 >、<、>=、<=。s.isdisjoint(z)查看而这是否有共同元素。
其他功能:
s.add(e)元素添加s.clear()移除所有元素s.copy()浅复制s.discard(e)若存在元素 e,则删除s.pop()移除一个元素并返回它的值s.remove(e)若存在元素 e,则删除;若不存在,则抛出异常
效率
字典和集合的查找效率:集合交集运算 > 集合内循环查找 > 字典内循环查找 > 列表内循环查找
字典背后是散列表,相当于一个稀疏数组,每个元素叫做表元(bucket)。
Python会保证大约三分之一的表元是空的,因此超过阈值时,散列表会被复制到新的大空间内。
因此,散列表用空间换时间,内存开销巨大。
往字典中添加新键,如果需要扩容,则需要复制散列表到新空间,这一过程可能产生散列冲突,导致键的次序打乱。
同理,不要同时字典进行迭代和修改。
扫描并修改一个字典:迭代获取需要修改的内容,放入新字典;迭代结束后更新原字典。
.keys(),.items()和.values()都是返回视图,是动态变化的。
文本和字节序列
以字符 é 为例:
1 | s = 'é' |
graph TD A[字符 é] === B["唯一编码(Unicode): U+00e9"] B === C["UTF-8 字节序列编码:b'\xc3\xa9'"] C === D["物理储存:11000011 10101001"]
元编程
动态属性与特性(property)
特性:property,不改变类接口,使用存取方法修改数据属性。
属性:attribute
多进程
多线程
threading 模块
CPython 具有 GIL 锁。GIL 锁是互斥锁,在解释器层保护共享数据。
CPython 解释器中,同一个进程下开启的多线程,同一时刻只能有一个线程执行,无法利用多核优势。
因此多线程适合用于 I/O 密集型任务,在 I/O 的等待时段,CPU 没有计算任务,因此其他线程可以执行。
附录
array
Type Code
| Type code | C Type | Minimum size in bytes |
|---|---|---|
| b | signed integer | 1 |
| B | unsigned integer | 1 |
| u | character | 2 (see note) |
| h | integer | 2 |
| H | unsigned integer | 2 |
| i | signed integer | 2 |
| I | unsigned integer | 2 |
| l | signed integer | 4 |
| L | unsigned integer | 4 |
| q | signed integer | 8 (see note) |
| Q | unsigned integer | 8 (see note) |
| f | floating point | 4 |
| d | floating point | 8 |
NOTE: The 'u' typecode corresponds to Python's unicode character. On narrow builds this is 2-bytes on wide builds this is 4-bytes. NOTE: The 'q' and 'Q' type codes are only available if the platform C compiler used to build Python supports 'long long', or, on Windows, '__int64'.
Methods
- append() -- append a new item to the end of the array
- buffer_info() -- return information giving the current memory info
- byteswap() -- byteswap all the items of the array
- count() -- return number of occurrences of an object
- extend() -- extend array by appending multiple elements from an iterable
fromfile()-- read items from a file object- fromlist() -- append items from the list
- frombytes() -- append items from the string
- index() -- return index of first occurrence of an object
- insert() -- insert a new item into the array at a provided position
- pop() -- remove and return item (default last)
- remove() -- remove first occurrence of an object
- reverse() -- reverse the order of the items in the array
tofile()-- write all items to a file object- tolist() -- return the array converted to an ordinary list
- tobytes() -- return the array converted to a string